
Management technischer Informationen
Sicher, flexibel und professionell
Sicher, flexibel und professionell
eDoc Dokumentverwaltung
Strukturierte Dokumente
Unstrukturierte Dokumente
Elektronische Signatur
Digitale Arbeitskarten
Technische Redaktion
Papierlose Archivierung
Formatkonvertierung
Analyse und Beratung
Software-Hosting
Betrieb und Support
Dokumenten Service
Unstrukturierte Dokumente
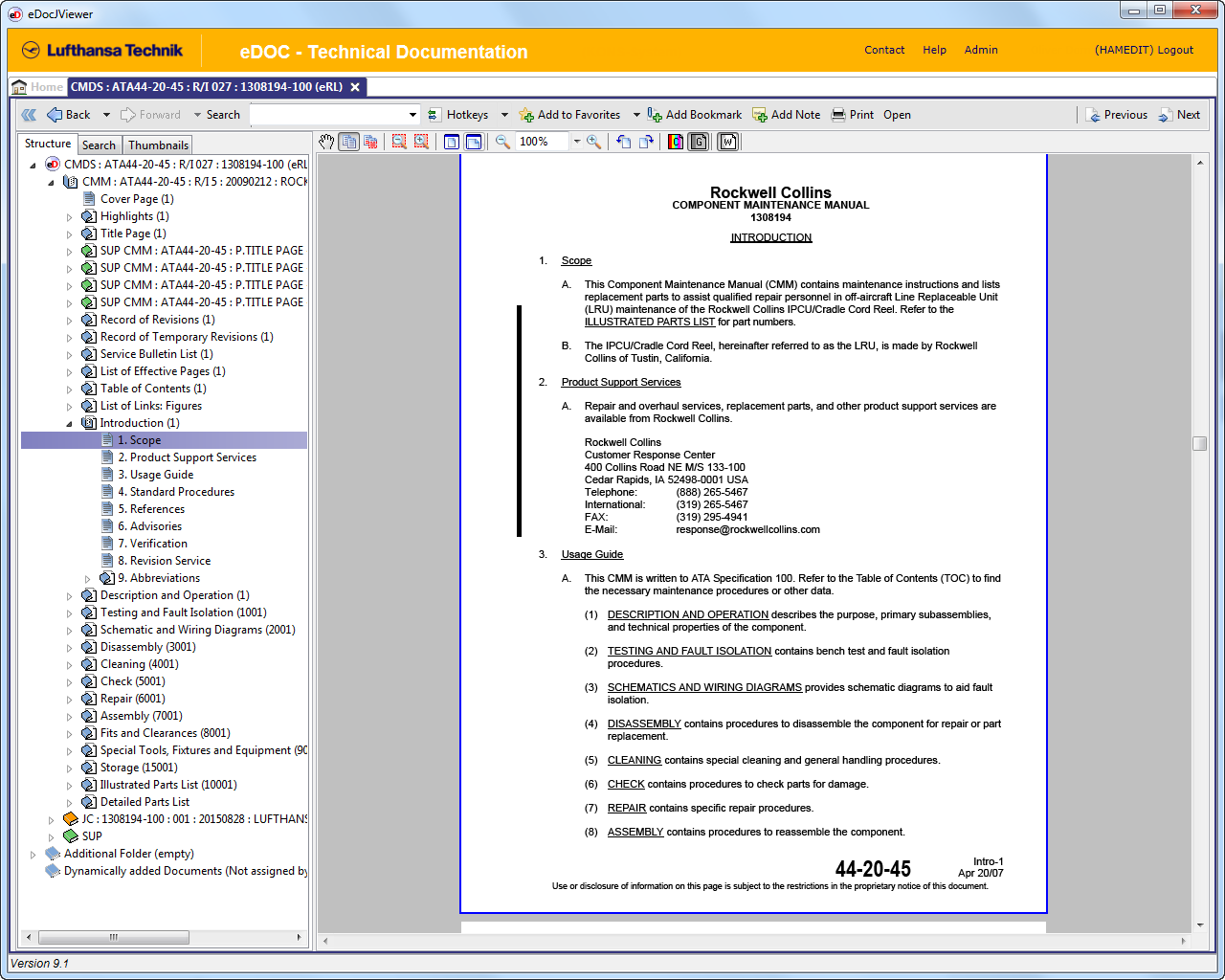 Trotz der vielfältigen Möglichkeiten moderner und strukturierter Datentypen sind PDF-Dokumente gerade bei vielen grossen, aber insbesondere bei kleinen Herstellern noch Standard.
Trotz der vielfältigen Möglichkeiten moderner und strukturierter Datentypen sind PDF-Dokumente gerade bei vielen grossen, aber insbesondere bei kleinen Herstellern noch Standard.
Dokumente identifizieren und eine standardisierte Struktur geben
Für eine weitgehend automatisierte Verarbeitung der eingehenden Dokumentation haben wir ein Modul realisiert (MAScan), das auf die Verarbeitung von grossen Mengen unstrukturierter Dokumente ausgelegt ist. Das Personal wird bei der Klassifizierung, der Erkennung von Duplikaten, der Strukturierung von PDF-Dokumenten und beim Auslesen komplexer Datenstrukturen unterstützt.
Datenextraktion - vorhandene Daten nutzen
Viele Dokumente enthalten sehr viele Daten, die erst nach einer strukturierten Extraktion ihr Potential entwickeln. Neben der Datenextraktion aus strukturierten Dokumentformaten wie XML, HTML, SGML und S1000D sind wir insbesondere auf das Erkennen von Datenstrukturen in PDF-Dokumenten spezialisiert (Extraktor).
Softwaregestützt definieren wir pro Dokumenttyp Ausleseschablonen und können so aus vermeintlich unstrukturierten Informationen weiterverwendbare Datenstrukturen erstellen.
| eDOC Aviation. All rights reserved | Impressum |