
Technical information management
Secure, flexible and professional
Secure, flexible and professional
eDoc Document Management
Structured Documents
Unstructured Documents
Electronic Signature
Digital Jobcards
Technical Editing
Paperless Archiving
Format Converting
Analysis and Consulting
Software Hosting
Operation and Support
Document Service
Unstructured Documents
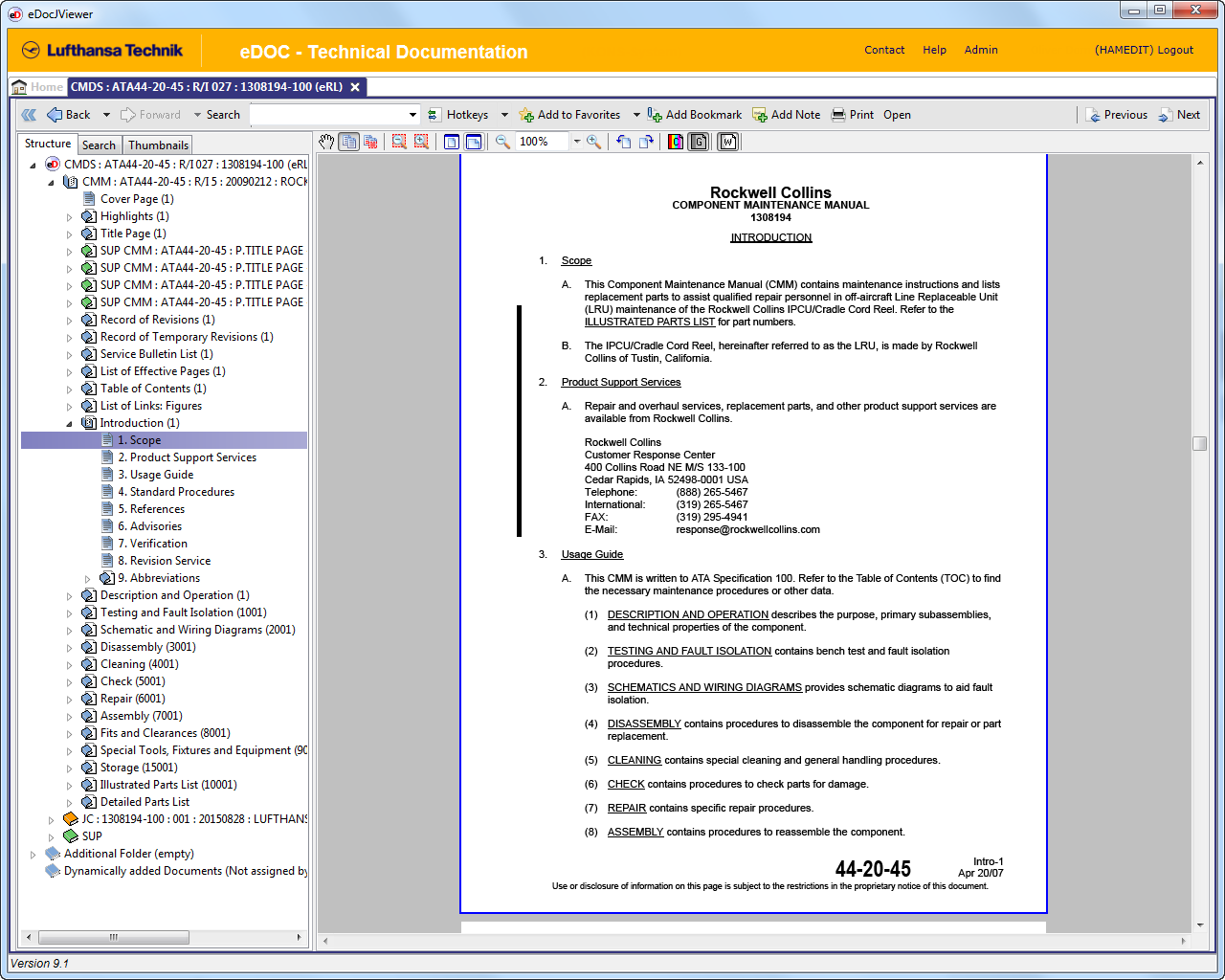 In spite of the numerous options provided by modern and structured data types, PDF documents are still the standard for many large, but also in particular small manufacturers.
In spite of the numerous options provided by modern and structured data types, PDF documents are still the standard for many large, but also in particular small manufacturers.
Identifying Documents and Providing a Standardized Structure
For broad automated processing of the incoming documentation we have realized a module (MAScan) which is designed for the processing of large numbers of unstructured documents. The staff is supported for the classification, identification of duplicates, structuring of PDF documents and the read-out of complex data structures.
Data Extraction - Using Existing Data
Numerous documents contain very much data which can only develop its potential after a structured extraction. Apart from the data extraction from structured document formats such as XML, HTML, SGML and S1000D, we are in particularly specialized in the recognition of data structures in PDF documents (Extraktor).
With software support we define read-out templates per document type and can create further utilizable data structures from alleged unstructured information.
| eDOC Aviation. All rights reserved | Impressum |